Data modelling is used in many processes including the development and integration of applications and the creation of analytics. Regardless of what a data model is being used for, it will:
- Show any data being stored e.g. Customer name, Product description
- Explain how the data is organised e.g. in a Customer table, Product table
- Indicate how the data relate to each other e.g. how a Product sale relates to a Customer
- Define the type of data e.g., a date, a number, some text
- Identify the Key fields, to recognise unique records e.g. Customer Id, Product Id
During the development of a data model there are normally three design stages:
- A conceptual data model aimed at displaying the key areas of data being included in the design.
- A logical data model design including details of the columns of data to be stored (attributes), key fields (identifiers) and how they relate to each other.
- A physical data model design, the lowest level of detail, showing everything in the logical design with the addition of data types and display names, it includes everything that will be stored within the physical database.
We’ll focus on the physical data model in this article, this will be the database that’s implemented in your organisation from a physical data model design.
Data will be stored and designed in different ways depending on its use, ensuring the design is optimised for its purpose. We will highlight the key differences between data stored for a business application and data stored for analysis.
Your business applications will store data in separate tables, each table containing data columns that only relate directly to a unique record (primary key) within that table, for example, a Customer table may contain a Customer Id (identifying a unique customer record) a Customer first name, Customer last name and Date of birth, all these items relate directly to the Customer Id.
Data that could change without affecting a table’s primary key or have more than one unique record will be stored in a separate table, e.g., a Customer address, the address could change without affecting a Customer’s ID, a customer may also have multiple addresses. (This is known as database normalization)
This type of application database has been designed to ensure data integrity, no duplicates are stored, each table is small and unique, data can be added, updated or deleted independently without impacting other application database tables.
The database described has been designed for a busines application, it’s not optimal for analysis. Performing complex analytical calculations or looking at data trends over time on this database would result in; queries that are difficult to write, data from many tables and knowledge of how they are related, its slow and its complicated.
Analytical data modelling will focus on presenting the analyst with information that is simplified, does not required multiple complicated joins, is easy to understand and quick for analysis. This data modelling is usually performed within a data warehouse (a database designed specifically for analysis) that stores information from many different business systems and from many different business processes.
There are many ways this can be designed, a common way its achieved is by Dimensional Modelling, where data is organised into tables called Dimensions and Facts.
Dimension tables contain data that relate to business entities e.g. Products, Customers and Stores, the tables will contain many columns and can be defined through understanding how the data will be analysed, grouped or filtered. Focus on the “by” word in your analytics requirements e.g. By product type, By Customer or By store.
Fact tables contain the measurements you need for analysis, and how they are joined to your dimensions, e.g., how much was spent, how long the transaction took or how many items were purchased, along with your key fields, Customer IDs , Product IDs and Store IDs. Fact tables do not necessarily need to contain measures, they can be used just to join dimensions together.
Fact and dimensions joined together in this way are referred to as a Star Schema.
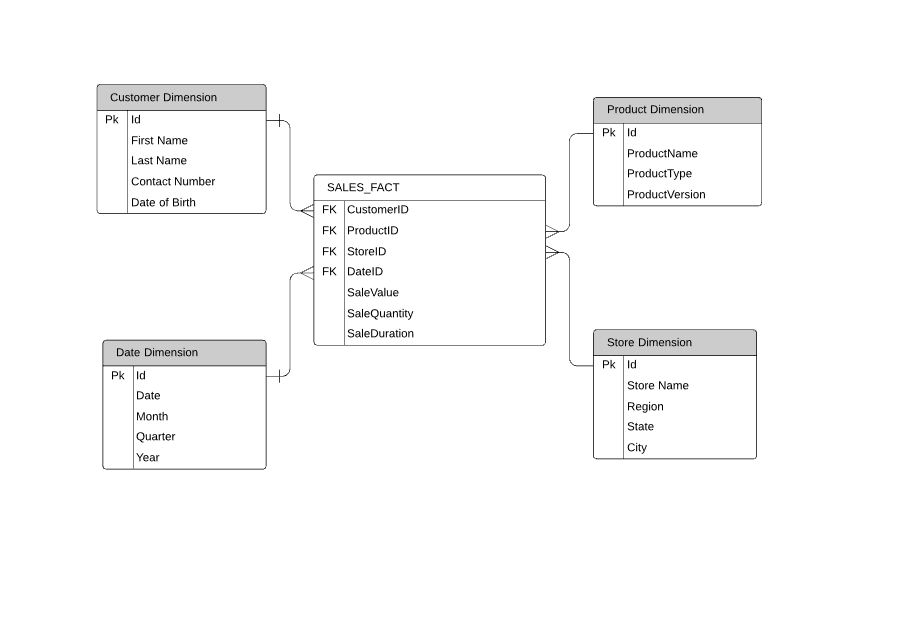
Depending on the technology used to implement these designs, they can be stored as cubes of data (essentially the star schema held in one component for analysis) or Tabular design (in separate tables that can be simply joined together)
This joined up data is referred to as a DataMart (a subset of the data in the data warehouse, targeted at a specific subject area to be analysed) they can be stored virtually or physically separate on the data warehouse.
Data modelling is a broad subject. You should now have an appreciation of why it’s important to design a data model based on what it will be used for. In future articles we will take a deeper dive into analytical data modelling.


